
Brefs rappels sur l’architecture Oracle
Architecture Oracle
L’architecture Oracle est rappelée dans le schéma qui suit :
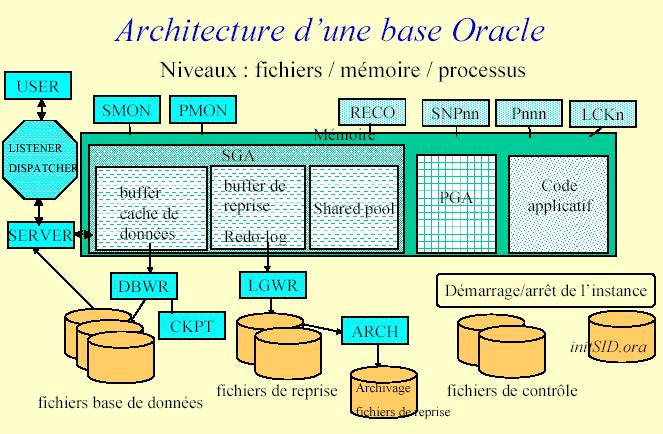
La zone mémoire Shared Pool est encore subdivisée en deux zones mémoires :
- Data Dictionnary Cache
- Library Cache
Processus Oracle
Ci-dessous sont résumées les tâches exécutées par les processus Oracle mentionnés dans le schéma de l’architecture oracle.
| Process | Description |
|---|---|
DBWR (Database Writer) |
Transfert les blocs de données modifiées du buffer
de données dansles fichiers disque de la base de
données Le paramètre d’initialisation
DB_WRITERS_PROCESSES permet de démarrer
plusieurs processus DBWR, afin d’augmenter le
taux d’écriture sur disque |
LGWR (Log Writer) |
Écrit les données modifiées depuis la zone mémoire redo-log buffer dans les fichiers redo-log |
CKPT (Checkpoint) |
Signe à intervalles réguliers le moment d’écriture des données modifiées de la SGA dans les fichiers de la base de données |
SMON (System Monitor) |
Surveille la base de données lors de son démarrage, puis au cours de son fonctionnement |
PMON (Processus Monitor) |
Nettoie les transactions défaillantes, comme celle d’un poste client qui s’arrête brutalement durant une transaction (zones allouées libérées, verrous supprimés, ressources affectées annulées) |
Vue associée : V$bgprocess
System Global Area (SGA)
La SGA est une zone mémoire qui regroupe un ensemble de structures de mémoire partagées qui contiennent les données et les informations de contrôle le plus souvent utilisées d’une instance Oracle.
Elle comprend
- Shared Pool Area (zone LC et zone DC)
- Data Buffer Cache ou buffer de données (tables, clusters, index)
- Redo-Log Buffer ou buffer de reprise
La SGA doit représenter au moins 2% de la taille totale de la base données (physique). Elle est répartie comme suit :
- 50% Cache de données (database buffer cache)
- 40% Shared Pool
- 10% Redo log Buffers
La vue V$SGASTAT permet d’interroger l’espace libre dans la SGA :
select * from v$sgastat where name='free memory'La mesure de la performance revient à calculer les différents indicateurs ratios d’analyse correspondants aux différentes parties de la SGA.
Shared Pool Area
C’est une partie de la SGA dans laquelle les instructions SQL, les procédures stockées et les informations spécifiques du dictionnaire sont enregistrées en mémoire.
Elle est gérée au moyen d’un algorithme LRU (Least Recently Used).
Elle comprend :
- Library Cache (zone LC) : contient le code SQL des instructions et les plans d’exécution associés, les blocs PL/SQL et les classes Java.
- Dictionary Cache (zone DC) : contient des méta données issues du dictionnaire de données décrivant la structure et la sécurité de tous les objets inclus dans les instructions SQL récemment utilisées.
Les paramètres d’instance associés au pool partagé sont :
SHARED_POOL_SIZE: définit la taille du pool partagé en octetsSHARED_POOL_RESERVED_SIZE: réserve une part du pool partagé pour des objets de grande taille (package, procédure, fonction)
Les vues dynamiques de performance associées sont : v$rowcache,
v$librarycache, v$sqlarea
Les principaux problèmes liés aux performances du pool partagé sont :
- une utilisation intense des ressources CPU, causé par des analyses excessives
- Erreur
ORA-4031: manque de place mémoire
Shared Pool Area (zone LC) - Library Cache
La zone LC contient les ordres SQL et blocs PL/SQL des utilisateurs.
Il est impératif de minimiser les phases d’analyse (parsing), ce qui revient à avoir le plus possible d’ordres, procédures… en mémoire.
Mesures de performance (v$librarycache)
La vue v$librarycache contient l’ensemble des informations relatives aux
activités de la Library cache depuis le dernier démarrage de l’instance.
desc v$librarycache;Nom de la colonne Null ? Type ----------------------------- ------ ----- NAMESPACE VARCHAR2(15) GETS NUMBER GETHITS NUMBER GETHITRATIO NUMBER PINS NUMBER PINHITS NUMBER PINHITRATIO NUMBER RELOADS NUMBER INVALIDATIONS NUMBER DLM_LOCK_REQUESTS NUMBER DLM_PIN_REQUESTS NUMBER DLM_PIN_RELEASES NUMBER DLM_INVALIDATION_REQUEST NUMBER DLM_INVALIDATIONS NUMBER
Pour chacun des items dans la zone LC (ordres SQL, procédures…)
| Item | Description |
|---|---|
gets |
nombre de requêtes pour un ou plusieurs éléments du cache de bibliothèque |
gethits |
nombre de fois q’un objet a été trouvé en mémoire |
gethitratio |
rapport entre gethits et gets |
pins |
nombre d’exécution d’un élément donné |
pinhits |
nombre de fois qu’un élément a été exécuté en mémoire |
pinhitratio |
rapport entre pinhits et pins |
reloads |
nombre de manqués (nombre de demandes infructueuses ayant nécessité
un rechargement en cache).
|
Exemple :
select namespace, gets, gethits, gethitratio, pins, pinhits, pinhitratio, reloads from v$librarycache; order by 1NAMESPACE GETS GETHITS GETHITRATI PINS PINHITS PINHITRATI RELOADS --------------- ------- ------- ---------- ---------- --------- ---------- -------- BODY 94 86 0,914893617 97 83 0,855670103 4 CLUSTER 3648 3639 0,997532895 4861 4847 0,997119934 1 INDEX 180116 120054 0,666537121 180115 120054 0,666540821 0 SQL AREA 951964 870446 0,914368611 13407693 13226440 0,986481418 15085 TABLE/PROCEDURE 207217 138097 0,666436634 410495 285940 0,696573649 22616 TRIGGER 143 138 0,965034965 206 120 0,582524272 63
Analyse des mesures
Library cache Hit Ratio :
select sum(pins-reloads)/ sum (pins) "Library cache hit ratio" from v$librarycache;Library cache hit ratio ---------------------------- ,997253872 ( > au seuil de 85%)
Si le Library cache Hit Ratio est < 85%, augmenter la valeur du paramètre
SHARED_POOL_SIZE.
Reload Ratio : le paramètre
reload ratio permet d’obtenir le pourcentage d’exécutions qui ont nécessité une
nouvelle analyse.
select sum(pins) "EXECUTIONS" , sum(RELOADS) "MISSES" , sum(RELOADS)/sum(pins) "RELOAD RATIO" from v$librarycache;EXECUTIONS MISSES RELOAD RATIO ----------- ------- ------------ 14069958 38637 ,274606363
select sum(pins) "EXECUTIONS" , sum(RELOADS) "MISSES" , sum(RELOADS)/sum(pins) "RELOAD RATIO" from v$librarycache where namespace = 'TRIGGER';EXECUTIONS MISSES RELOAD RATIO ----------- ------- ------------ 337 87 ,258160237
Si la valeur reload-ratio est > 1, augmenter la valeur du paramètre
SHARED_POOL_SIZE.
Solutions et recommandations
En fonction des résultats obtenus à partir de la vue v$librarycache :
- augmenter la valeur
SHARED_POOL_SIZEdans le fichierinitSID.ora - utiliser des procédures génériques (packages, procédures/fonctions)
- même texte pour la même requête
- référencer les objets par les mêmes noms
Identification des objets de grande taille
Il est particulièrement utile de connaître les objets de grande taille qui
montent dans la mémoire Library Cache. La vue dynamique v$db_object_cache
permet de connaître la mémoire utilisée par les objets dans la zone LC.
Lorsqu’une procédure incluse dans un package est appelée, c’est l’ensemble du package qui est chargé en mémoire et analysé.
select name, type, loads, executions from v$db_object_cache where type in ('PACKAGE', 'PACKAGE BODY','FUNCTION','PROCEDURE') and owner like 'SCOTT%'NAME TYPE LOADS EXECUTIONS SHARABLE_M ---- ---- ----- ---------- ---------- NBCUSTOMER PROCEDURE 3 9 8070 COMMAND_EXISTS FUNCTION 2 17 13333 PREVIEW PROCEDURE 3 61 9218 MAJOR PROCEDURE 6 7 8335
Shared Pool Area (zone DC) - Data Dictionary Cache
La zone DC contient les objets du dictionnaire et l’objectif est de minimiser les défauts de mémoire pour le cache dédié au dictionnaire.
Mesures de performances
La vue v$rowcache contient l’ensemble des informations relatives aux
activités de la zone DC depuis le dernier démarrage de l’instance.
desc v$rowcache;Nom de la colonne Null ? Type ---------------- ------ ----- CACHE# NUMBER TYPE VARCHAR2(11) SUBORDINATE# NUMBER PARAMETER VARCHAR2(32) COUNT NUMBER USAGE NUMBER FIXED NUMBER GETS NUMBER GETMISSES NUMBER SCANS NUMBER SCANMISSES NUMBER SCANCOMPLETES NUMBER MODIFICATIONS NUMBER FLUSHES NUMBER DLM_REQUESTS NUMBER DLM_CONFLICTS NUMBER DLM_RELEASES NUMBER
| Paramètre | Nom de l’élément du dictionnaire de données |
|---|---|
gets |
Cumul des demandes d’informations sur l’élément |
getmisses |
Cumul des demandes manqués sur l’élément |
Analyse des mesures
Dictionary cache hit ratio
select (sum(gets-getmisses))/sum(gets)*100 "Dictionary Cache Hit ratio" from v$rowcache;Dictionary ---------- 94,0434197
Une valeur du Dictionary Cache Hit Ratio > 85% est satisfaisante.
Solutions et recommandations
Lorsque le paramètre Dictionary cache hit ratio est trop faible, augmenter
la valeur du paramètre SHARED_POOL_SIZE.
Buffer cache de données
Fonctionnement
Les données sont écrites en mémoire par blocs avant de pouvoir être manipulées en lecture ou en écriture.
La quantité disponible pour enregistrer ces blocs est limité, de telle sorte que des blocs doivent être remplacés par des blocs plus récents en suivant un mécanisme de gestion LRU.
Un bloc est dit dirty si son contenu a changé. Oracle n’autorise pas de nouvelles données à prendre cette place, tant que ce contenu n’a pas été écrit sur disque.
Une fois le bloc écrit sur le disque, il devient disponible pour être réutilisé, il est dit free.
L’objectif est de minimiser les accès aux fichiers de données et éviter ainsi les lectures sur disque, en privilégiant le nombre d’accès mémoire.
Paramètres de configuration
DB_BLOCK_SIZE(Taille d’un bloc en octets)DB_BLOCK_BUFFERS(Nombre de blocs qui peuvent être enregistrés)
La taille d’un bloc détermine la taille de chacun des buffers.
Mesures de performances, Cache hit ratio (v$sysstat)
C’est le rapport entre le nombre de fois où un bloc est demandé et le nombre de fois où le cache de données d’Oracle a été capable de renvoyer la valeur par une lecture logique plutôt que par une lecture physique.
db block gets: nombre d’accès aux blocs non RBS (Rollback Segments)consistent gets: nombre d’accès aux blocs RBS (Rollback Segments), consistancephysical reads: nombre de lecture de blocs sur disque.
select 1- (phy.value / ( cons.value + db.value - phy.value))
from v$sysstat phy, v$sysstat cons, v$sysstat db
where phy.name ='physical reads'
and cons.name ='consistent gets'
and db.name ='db block gets'La requête ci-dessous permet de traquer les objets qui utilisent la plus grande part du cache de données :
Select o.owner, o.object_type, o.object_name, count(b.objd) from v$bh, dba_objects o
where b.objd=o.objects_id
group by o.owner, o.object_type, o.object_name
having count(b.objd) > (select to_number(value*0.5) from v$parameter
where name='db_block_buffers')La valeur optimale pour le cache hit ratio est >= 90%.
Mesures de performances, les évènements d’attente (v$session_wait)
La vue v$session_wait permet de déterminer les évènements d’attente qui
affectent le cache de données :
Select SW.Sid, S.Username, Substr(SW.Event,1,35), SW.Wait_Time
from v$session S, v$session_wait SW
where SW.Event not like 'SQl*Net%'
and SW.Sid=S.Sid
Order by SW.Wait_Time, SW.EventLes évènements d’attente courants relatifs au cache de données sont :
| Item | Description |
|---|---|
Buffer busy waits |
Indique une attente d’un buffer dans le cache de la base de données |
Free buffer waits |
Manque de buffers libres dans le cache de données |
Db file sequential read |
Signale des attentes associées à une lecture excessive d’index |
Db file scattered read |
Signale des attentes associées à un balayage complet d’une table |
Solutions et recommandations
Pour résoudre les problèmes de performance sur le cache hit ratio
- augmenter la valeur du paramètre
DB_BLOCK_BUFFERS - utiliser la mémoire cache pour les tables
Buffer de reprise (redo log buffer)
Fonctionnement
- Un processus utilisateur lance une commande DML
- Oracle affecte un identificateur de transaction à cette opération
- Le processus serveur associé au processus utilisateur transfère en mémoire les données nécessaires, puis verrouilles les lignes concernées qui doivent subir des manipulations
- Le processus serveur écrit dans le redo log buffer l’image des lignes avant les modifications (before image)
- Le processus serveur met à jour les lignes de données
- Le processus serveur écrit dans le redo log buffer l’image qui suit la transaction (after image)
- Les données du redo log buffer sont transcrites sur disque lorsque survient l’un des évènements suivants
- Chaque fois qu’une période de trois secondes s’est écoulée
- Lors d’un commit
- Lorsque l’expression
MIN(1MB, LOG_BUFFER/3)est vérifiée - Au moment des checkpoints
- Lorsqu’il est déclenché par le processus DBWR
Ce buffer est géré cycliquement.
D’une manière globale, le buffer de redo log contient les modifications effectuées sur les données à travers un redo entry : bloc modifié, localisation de la modification dans le bloc, nouvelle valeur.
Paramètre de configuration
LOG_BUFFER dans le fichier de configuration de l’instance définit la
taille en octets.
Evènements d’attente liés au redo log buffer
| Item | Description |
|---|---|
Log buffer space |
indique un problème potentiel du LGWR |
Log file parallel write |
signale une attente liée à l’écriture des journaux sur le disque |
Log file sync |
signale des attentes liées à un vidage du journal lors de la validation (commit) par un utilisateur |
Mesures de performances
redo buffer retries ratio : v$sysstat
"redo buffer allocation retries" dans la vue v$sysstat indique le nombre
d’attente avant d’écrire dans le redo log buffer.
select name, value from v$sysstat where name in ('redo buffer allocation retries','redo entries');NAME VALUE -------------------------------- ------- redo entries 2674558 redo buffer allocation retries 83
select 100*(a.value/b.value) "redo buffer retries ratio" from v$sysstat a, v$sysstat b where a.name='redo buffer allocation retries' and b.name='redo entries';redo buffer retries ratio ----------------------------- 0,003102836
Attente due à la non disponibilité du fichier redo log
Select name, value from v$sysstat where name='redo log space requests';NAME VALUE ---------------------------- -------- redo log space requests 64
Solutions et recommandations
Pour résoudre les problèmes de performance sur le buffer de reprise
- augmenter la valeur du paramètre
LOG_BUFFER
Statpack
Objectifs et Installation
Statpack est un outil de diagnostic qui enregistre un grand nombre de données relatives aux performances. Le calcul des ratios est effectué.
Les données sont enregistrées dans un schéma particulier permettant une utilisation ultérieure. Il est possible de faire une comparaison avec les données d’exécution antérieures.
L’installation s’effectue avec la création du schéma statpack et du user
PERFSTAT : lancer le script $ORACLE_HOME/rdbms/admin/spcreate.sql
Pour exécuter un rapport de stats :
connect perfstat/perfstat;
execute statpack.snap;Pour afficher le rapport :
@?/rdbms/admin/spreport.sql;Exemple de rapport
STATSPACK report for
DB Name DB Id Instance Inst Num Release OPS Host
---------- ----------- ---------- -------- ---------- ---- ----------
Test 204079298 ORCL 1 8.1.5.0.0 NO azuro
Snap Length
Start Id End Id Start Time End Time (Minutes)
-------- -------- -------------------- -------------------- -----------
1 2 25-Sep-00 00:36:21 25-Sep-00 00:38:10 1.82
Cache Sizes
~~~~~~~~~~~
db_block_buffers: 8192
db_block_size: 2048
log_buffer: 163840
shared_pool_size: 15728640
Load Profile
~~~~~~~~~~~~
Per Second Per Transaction
--------------- ---------------
Redo size: 4,893.39 533,380.00
Logical reads: 37.88 4,129.00
Block changes: 22.23 2,423.00
Physical reads: 4.26 464.00
Physical writes: 7.16 780.00
User calls: 0.02 2.00
Parses: 2.04 222.00
Hard parses: 0.06 7.00
Sorts: 0.35 38.00
Instance Efficiency Percentages (Target 100%)
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Buffer Nowait Ratio: 100.00
Buffer Hit Ratio: 88.76
Library Hit Ratio: 94.08
Redo NoWait Ratio: 99.69
In-memory Sort Ratio: 94.74
Soft Parse Ratio: 96.85
Latch Hit Ratio: 100.00