
Introduction
Grande nouveauté de la base de données time series InfluxDB v2 et de son langage Flux : les passerelles vers les moteurs de bases de données SQL (PostgreSQL, MySQL, Microsoft SQL Server…). Encore plus de pilotes de bases de données à venir dans les prochaines versions.
Pour récupérer et pousser des données depuis/vers des bases de données SQL, 2 fonctions simples : sql.from et sql.to.
Dans cet article :
- Des données time series sont enrichies et des variables de tableaux de bords (dashboards) sont renseignées
avec des données de référence provenant de bases de données SQL avec la fonction
sql.from. - Les données agrégées sont stockées pour du long terme dans des bases de données SQL avec la fonction
sql.to. Le mécanisme est décrit.
Des considérations spécifiques sont abordées sur les conversions des types de données.
Pour les débutants dans le langage Flux et/ou habitués à InfluxQL, d’autres publications sont disponibles sur SQLPAC :
- InfluxDB, Passer du langage InfluxQL au langage Flux
- InfluxDB v2 : langage Flux, aide-mémoire
- InfluxDB : Langage Flux, fonctionnalités avancées
Le dernier article cité aborde comment réaliser des jointures avec le langage Flux.
Gérer les paramètres de connexion (secrets)
Selon le driver utilisé (PostgreSQL, MySQL, MS SQL Server…), la chaîne de connexion DSN a des nomenclatures différentes :
| PostgreSQL | |
| MySQL | |
| MS SQL Server | |
Liste complète des syntaxes DSN des drivers disponibles : InfluxData - Driver dataSourceName examples
Éviter les chaînes de connexion codées en dur dans les scripts Flux, définir autant que possible tous les paramètres de connexion
aux bases de données (urls, noms d’utilisateur, mots de passe, port…) dans des secrets avec le client influx en lignes de commandes (cf Annexe pour l’utilisation du client influx).
Les secrets sont des paires clé-valeur qui contiennent des informations sensibles auxquelles on souhaite contrôler l’accès, telles que des clés API, des mots de passe ou des certificats…
Les secrets sont stockés dans cet article dans la base bolt du serveur InfluxDB (paramètre de démarrage du serveur : bolt-path = "/sqlpac/influxdb/srvifx2sqlpac/srvifxs2qlpac.bolt").
Création des secrets
Le secret POSTGRES_DSN stockant le DSN en entier est créé avec le client influx :
$ influx secret update --key POSTGRES_DSN \
--value "postgresql://influxdb:""**********""@vpsfrsqlpac?port=30008&sslmode=disable"Dans l’exemple ci-dessus, le mot de passe contient des caractères spéciaux, il est échappé avec "".
Le choix a été fait ici de stocker le DSN complet dans un secret, on peut décider de créer un secret par option de connexion :
$ influx secret update --key POSTGRES_HOST --value "vpsfrsqlpac"
$ influx secret update --key POSTGRES_USER --value "influxdb"
…Récupération des secrets dans les scripts Flux
Dans les scripts Flux, un secret est extrait avec le package secrets :
import "influxdata/influxdb/secrets"
POSTGRES_DSN = secrets.get(key: "POSTGRES_DSN")import "influxdata/influxdb/secrets"
POSTGRES_HOST = secrets.get(key: "POSTGRES_HOST")
POSTGRES_USER = secrets.get(key: "POSTGRES_USER")
…Interrogation de bases de données SQL, sql.from
Très facile d’interroger les bases de données SQL à l’aide du package sql et de sa fonction from, le code n’a pas besoin de commentaires :
import "sql" import "influxdata/influxdb/secrets" POSTGRES_DSN = secrets.get(key: "POSTGRES_DSN") sql.from( driverName: "postgres", dataSourceName: "${POSTGRES_DSN}", query: "SELECT name, totalmemory, \"date creation\" FROM vps WHERE name like \"vps%\"" )Result: _result Table: keys: [] name:string totalmemory:int date creation:time ---------------------- -------------------------- ------------------------------ vpsfrsqlpac1 4000 2020-09-18T00:00:00.000000000Z vpsfrsqlpac2 2000 2020-09-25T00:00:00.000000000Z vpsfrsqlpac3 2000 2020-09-29T00:00:00.000000000Z
Selon le pilote, les traductions des types de données de la base de données source vers InfluxDB peuvent différer. Faire attention aux conversions de types de données.
| MySQL | InfluxDB | PostgreSQL | InfluxDB | |
|---|---|---|---|---|
char, varchar |
string |
char, varchar |
string |
|
float |
float |
double precision (float) |
float |
|
integer |
integer |
integer |
integer |
|
decimal |
string |
numeric |
string |
|
date, time, timestamp |
string |
date, time, timestamp |
time |
|
datetime |
time |
Pourquoi interroger des bases de données SQL ? 2 utilisations courantes :
- Enrichir des données avec des données de référence non disponibles dans les mesures.
- Renseigner des variables de tableaux de bord du GUI InfluxDB.
Enrichir les données - Jointures
Les mesures ne stockent pas toutes les données nécessaires. Des jointures peuvent être effectuées avec des données de référence extraites de bases de données SQL pour enrichir les données.
Un exemple : la mesure vps_pcpumem stocke la mémoire utilisée par host dans le champ mem.
vps_pcpumem,host=vpsfrsqlpac1 pcpu=22,mem=738 …
vps_pcpumem,host=vpsfrsqlpac1 pcpu=37,mem=772 …La mémoire totale n’est pas disponible dans la mesure et on souhaite calculer le pourcentage de mémoire utilisé.
Sachant que la mémoire totale par host est disponible dans une table PostgreSQL : vps (name varchar(30), totalmemory int)
SELECT name, totalmemory FROM vpsname | totalmemory --------------+------------- vpsfrsqlpac1 | 4000 vpsfrsqlpac2 | 2000
Effectuons une jointure pour atteindre l’objectif :
import "influxdata/influxdb/secrets" POSTGRES_DSN = secrets.get(key: "POSTGRES_DSN") datavps = sql.from( driverName: "postgres", dataSourceName: "${POSTGRES_DSN}", query: "SELECT name as host, totalmemory FROM vps" ) datamem = from(bucket: "netdatatsdb/autogen") |> range(start: -1d) |> filter(fn: (r) => r._measurement == "vps_pcpumem" and r._field == "mem" and r.host == "vpsfrsqlpac1") join( tables: {vps:datavps, mem:datamem}, on: ["host"], method: "inner" ) |> map(fn: (r) => ({ r with pmem: (r._value / float(v: r.totalmemory)) * 100.0 })) |> rename(columns: { _value:"mem" }) |> keep(columns: ["_time","host","mem","pmem"])Result: _result Table: keys: [host] host:string _time:time mem:float pmem:float ---------------------- ------------------------------ ---------------------------- ---------------------------- vpsfrsqlpac1 2021-03-04T12:46:27.525578148Z 935 23.375 vpsfrsqlpac1 2021-03-04T12:47:27.886245623Z 989 24.725
Dans la fonction map, totalmemory est convertie en float
car le type de données de la colonne source est integer. Avec la fonction map,
les types de données doivent correspondre sinon une erreur de conflit est levée.
Error: Runtime error @25:6-25:75: map: type conflict: float != int.Une autre approche : la conversion en type float est réalisée en amont dans la requête SQL source.
…
datavps = sql.from(
driverName: "postgres",
dataSourceName: "${POSTGRES_DSN}",
query: "SELECT name as host, cast(totalmemory as float) FROM vps"
)
…
join(
tables: {vps:datavps, mem:datamem},
on: ["host"],
method: "inner"
)
|> map(fn: (r) => ({ r with pmem: (r._value / r.totalmemory) * 100.0 }))
…Renseigner les variables des tableaux de bord du GUI InfluxDB
Les requêtes SQL sont très utiles pour renseigner les variables des tableaux de bord du GUI InfluxDB avec des données de référence : champs, listes déroulantes…
Dans le tableau de bord exemple ci-dessous, la liste déroulante des serveurs est construite à partir de la table PostgreSQL vps :
Une variable appelée server est créée. Le script Flux interrogeant PostgreSQL est attachée à la variable : dans le code Flux,
le nom de la colonne source (name) est renommée en _value et seule la colonne _value est retournée
avec la fonction keep.
Dans un panneau d’un tableau de bord, le filtre est appliqué dans la requête Flux en utilisant cette nouvelle variable v.server :
|> filter(fn: (r) => r["host"] == v.server)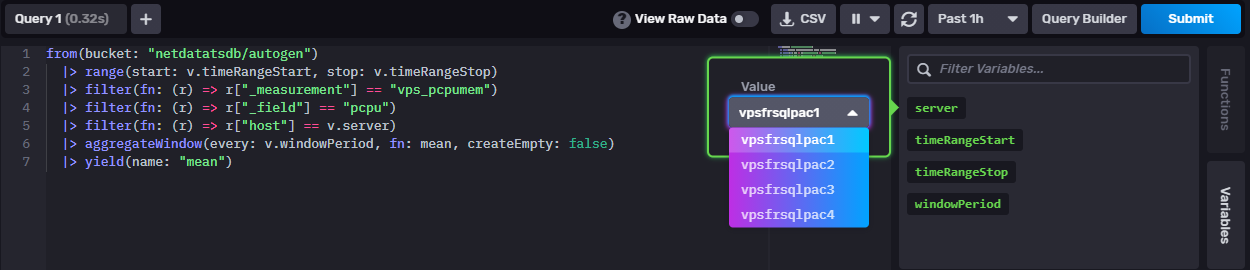
Un petit mot à propos de Grafana : la méthodologie est la même, la requête Flux qui récupère les données de la base de données SQL est attachée à une variable.
Par rapport au GUI InfluxDB, dans Grafana ne pas oublier d’appeler la fonction yield et garder à l’esprit
que les requêtes Flux ne sont supportées qu’à partir de Grafana 7.1.
import "sql"
import "influxdata/influxdb/secrets"
POSTGRES_DSN = secrets.get(key: "POSTGRES_DSN")
datavps = sql.from(
driverName: "postgres",
dataSourceName: "${POSTGRES_DSN}",
query: "SELECT name FROM vps"
)
|> rename(columns: { name:"_value" })
|> keep(columns: ["_value"])
|> yield()Écrire dans les bases de données SQL, sql.to
La fonction InfluxDB sql.from extrait les données de bases de données SQL. La fonction sql.to pousse
les données vers une base SQL. Les syntaxes sql.from et sql.to sont analogues.
Une fonctionnalité très intéressante pour stocker des données agrégées pour du long terme,
en particulier si la période de rétention n’est pas infinie dans les serveurs InfluxDB.
Dans l’exemple de code ci-dessous, les données sont poussées dans la table PostgreSQL vpspmem, table déjà créée :
import "sql"
import "influxdata/influxdb/secrets"
POSTGRES_DSN = secrets.get(key: "POSTGRES_DSN")
from(bucket: "netdatatsdb/autogen")
|> range(start: -1d)
|> filter(fn: (r) => r._measurement == "vps_pmem"
and r._field == "pmem"
and r.host == "vpsfrsqlpac2")
|> aggregateWindow(every: 1h, fn: mean, createEmpty: false)
|> rename(columns: {_value: "pmem", _time: "dth"})
|> keep(columns: ["host", "dth", "pmem"])
|> sql.to(
driverName: "postgres",
dataSourceName: "${POSTGRES_DSN}",
table: "vpspmem"
)CREATE TABLE vpspmem (
host varchar(30) not null,
dth timestamp not null,
pmem float not null
)Les noms des colonnes, les types de données, les caractéristiques NULL/NOT NULL doivent correspondre.
Un exemple d’erreur (NULL) :
! sql: transaction has already been committed or rolled back:
runtime error @14:6-18:6: to: pq:
null value in column "pmem" violates not-null constraintPourquoi d’abord créer la table ? Dans les coulisses, la fonction sql.to tente de créer la table si elle n’existe pas,
mais dans l’instruction CREATE TABLE générée, le type de données string InfluxDB est converti en type TEXT
qui n’est pas approprié pour l’indexation et la maintenance, des types de données plus précis (varchar) sont préférables :
- PostgreSQL :
2021-03-07 18:13:13.101 CET LOG: statement: CREATE TABLE IF NOT EXISTS vpspmem (dth TIMESTAMP,pmem FLOAT,host TEXT) - MySQL :
2021-03-05T17:41:47.737575Z 12 Query CREATE TABLE IF NOT EXISTS vpspmem (dth DATETIME,pmem FLOAT,host TEXT(16383))
Comment les écritures sont réalisées ? Pour PostgreSQL et MySQL, des commandes préparées (prepared statements) sont envoyées au sein d’une transaction :
2021-03-05 18:31:18.154 CET LOG: statement: BEGIN READ WRITE
2021-03-05 18:31:18.157 CET LOG: statement: CREATE TABLE IF NOT EXISTS vpspmem (dth TIMESTAMP,pmem FLOAT,host TEXT)
2021-03-05 18:31:18.157 CET NOTICE: relation "vpspmem" already exists, skipping
2021-03-05 18:31:18.159 CET LOG: execute <unnamed>: INSERT INTO vpspmem (dth,pmem,host) VALUES ($1,$2,$3),($4,$5,$6), …
2021-03-05 18:31:18.159 CET DETAIL: parameters: $1 = '2021-03-04 16:00:00', $2 = '25.999999999999996', $3 = 'vpsfrsqlpac2',
$4 = '2021-03-04 17:00:00', $5 = '27.66186440677966', $6 = 'vpsfrsqlpac2', …
2021-03-05 18:31:18.160 CET LOG: statement: COMMITLe nombre maximum de colonnes ou de paramètres dans chaque instruction préparée est par défaut 10000 (batchsize).
Si nécessaire, le paramètre batchsize peut être ajusté dans la fonction sql.to :
|> sql.to(
driverName: "postgres",
dataSourceName: "${POSTGRES_DSN}",
table: "vpspmem",
batchsize: 50000
)Annexe - client influx
Avant de pouvoir utiliser le client influx, la config (url, token, org…) est d’abord définie.
$ export INFLUX_CONFIGS_PATH=/sqlpac/influxdb/srvifx2sqlpac/configs
$ export INFLUX_ACTIVE_NAME=default/sqlpac/influxdb/srvifx2sqlpac/configs :
[default]
url = "https://vpsfrsqlpac:8086"
token = "K2YXbGhIJIjVhL…"
org = "sqlpac"
active = trueExemple d’utilisation du client influx :
$ influx secret listKey Organization ID PG_HOST 4dec7e867866cc2f PG_PASS 4dec7e867866cc2f PG_PORT 4dec7e867866cc2f PG_USER 4dec7e867866cc2f