
Introduction
Le guide pratique "Sybase Adaptive Server Enterprise 15.0.2 : Outils de diagnostic et de tuning, aide-mémoire" publié en 2009 sur SQLPAC présentait les commandes utiles nécessaires au diagnostic de traitements.
La présente note va les mettre en musique dans l’étude d’un cas pratique détaillé, le but étant de se familiariser avec les outils et leur résultat.
Contexte
Soit la requête suivante, intégrée au sein d’une procédure, simplifiée pour l’exemple
create procedure sp_test
@process_date datetime
as
begin
SELECT 'NAME' = f.PORTFOLIO_NAME,
'TOTAL' = SUM(t.TOTAL_NET_AMT)
into #tmp
FROM TRADE t
join tmp_filtre f on f.PORTFOLIO_ID = f.PORTFOLIO_ID
WHERE t.TRADING_DATE <= @process_date
AND t.SETTLEMENT_DATE > @process_date
AND t.TRANSACTION_CATEGORY = 'C'
GROUP BY f.PORTFOLIO_NAME
end
goElle est exécutée quotidiennement, la date passée en paramètre correspond à la date du jour et sa durée d’exécution est de quelques secondes.
Le souci survient lorsque soudainement cette procédure dure plusieurs dizaines de minutes au lieu des quelques secondes habituelles.
Observation
Plan d’exécution
Pour comprendre les raisons de la lenteur, il est important de connaître le
plan d’exécution en cours, plan d’exécution donné par la procédure
sp_showplan.
execute sp_showplan 307,null,null,nullQUERY PLAN FOR STATEMENT 2 (at line 5). STEP 1 The type of query is CREATE TABLE. STEP 2 The type of query is INSERT. 6 operator(s) under root |ROOT:EMIT Operator (VA = 6) | | |INSERT Operator (VA = 5) | | The update mode is direct. | | | | |HASH VECTOR AGGREGATE Operator (VA = 4) | | | GROUP BY | | | Evaluate Grouped SUM OR AVERAGE AGGREGATE. | | | Using Worktable3 for internal storage. | | | Key Count: 1 | | | | | | |MERGE JOIN Operator (Join Type: Inner Join) (VA = 3) | | | | Using Worktable2 for internal storage. | | | | Key Count: 1 | | | | Key Ordering: ASC | | | | | | | | |SORT Operator (VA = 1) | | | | | Average Row width is 13.278074 | | | | | Using Worktable1 for internal storage. | | | | | | | | | | |SCAN Operator (VA = 0) | | | | | | FROM TABLE | | | | | | TRADE | | | | | | t | | | | | | Table Scan. | | | | | | Forward Scan. | | | | | | Positioning at start of table. | | | | | | Using I/O Size 16 Kbytes for data pages. | | | | | | With MRU Buffer Replacement Strategy for data pages. | | | | | | | | |SCAN Operator (VA = 2) | | | | | FROM TABLE | | | | | tmp_filtre | | | | | f | | | | | Using Clustered Index. | | | | | Index : pk | | | | | Forward Scan. | | | | | Positioning by key. | | | | | Keys are: | | | | | PORTFOLIO_ID ASC | | | | | Using I/O Size 16 Kbytes for data pages. | | | | | With LRU Buffer Replacement Strategy for data pages. | | | | TO TABLE | | #tmp | | Using I/O Size 16 Kbytes for data pages.
On observe que la table #tmp_filtre est accédée par son index cluster *pk*
tandis que la table TRADE est parcourue entièrement ( Table Scan )
Une procédure alternative sp__showplan, procédure développée par Ed Barlow,
permet de s’affranchir des 3 derniers paramètres :
execute sp__showplan 307Événements d’attente
On se doute que le *table Scan* sur la table TRADE est la cause logique de
la lenteur. Il est possible d’observer le comportement *physique* de l’instance
lors de son exécution. La lecture des évènements d’attente ( Wait Events )
associés au processus peut être nécesaire.
Ces informations sont accessibles par l’intermédiaire de la table MDA
monProcessWaits :
select 'SPID' = p.SPID, 'Login' = suser_name(p.ServerUserID) , 'Waits' = p.Waits, 'WaitTime' = p.WaitTime, 'Event' = e.Description , 'Class' = c.Description from master.dbo.monProcessWaits p join master.dbo.monWaitEventInfo e on e.WaitEventID = p.WaitEventID join master.dbo.monWaitClassInfo c on c.WaitClassID = e.WaitClassID where p.SPID=307 order by WaitTime desc goSPID Login Waits WaitTime Event Class ---- ----- ----- -------- ------------------------------------------------ ------------------------------ 307 test 681 3700 wait for mass read to finish when getting page w. for internal system event 307 test 550 1200 waiting for regular buffer read to complete w. for a disk read to complete 307 test 3 0 waiting on run queue after yield w. to be scheduled 307 test 3 0 waiting for network send to complete w. to output to the network 307 test 1 0 waiting for buf write to complete before writing w. for a disk write to complete
Ici on observe que la lecture d’information sur disque est la cause de la
lenteur (mass read/internal + buffer read/disk).
La procédure SQLPAC sp_dba_getwe <SPID> simplifie l’accès aux
informations de cette table monProcessWaits en historisant l’interrogation afin
de réaliser des calculs différentiels, mais aussi de présenter l’information
avec plusieurs niveaux de détail.
execute sp_dba_getwe 307,2Cls Description T_Waits T_Seconds dtFrom dtTo Waits Seconds sPct --- ------------------------ ------- --------- -------- -------- ----- ------- ---- 1 to be scheduled 1 0 15:24:56 15:25:28 0 0 0 2 a disk read to complete 8979 15 15:24:56 15:25:28 6210 12 37 3 a disk write to complete 1 0 15:24:56 15:25:28 0 0 0 7 input from the network 4 0 15:24:56 15:25:28 0 0 0 8 to output to the network 2 0 15:24:56 15:25:28 0 0 0 9 internal system event 5066 23 15:24:56 15:25:28 4120 20 62
Présence des données en cache
Un SGBD est, entre autre, un cache de données. Ce qui est lu est conservé en
mémoire autant que possible évitant ainsi de coûteux accès disques. Aussi, un
'Table Scan' peut ne pas avoir d’impact majeur sur la durée d’exécution d’un
processus si toutes les données sont disponibles en mémoire.
Dans l’exemple présent, les évènements d’attente ont montré que la longueur d’exécution du processus provenait de la lecture des informations sur disque.
La table MDA monCachedObject mesure la présence d’un objet en
cache.
select 'Cache' = c.CacheName, 'Tbl' = c.ObjectName , 'CachedMb' = c.CachedKB / 1024 , 'SizeMb' = c.TotalSizeKB / 1024 , 'Pct' = 100 * c.CachedKB / c.TotalSizeKB from master.dbo.monCachedObject c where c.IndexID in ( 0, 1 ) and c.DBID=db_id() and c.ObjectName in ( 'TRADE', 'tmp_filtre' )Cache Tbl CachedMb SizeMb Pct ------------------------------ ------------------------- ----------- ----------- ----------- default data cache TRADE 439 5145 8 default data cache tmp_filtre 0 0 100
La taille des objets est à présent mesurée. La plus grosse table, TRADE,
occupe plus de 5 Go de données, dont moins de 500 Mo sont déjà en cache. La
durée d’exécution donc dépendra essentiellement du temps qu’il faudra pour lire
les 4,5 Go absents du cache depuis le disque.
La procédure SQLPAC sp_dba_getobj simplifie l’interrogation de cette table
monCachedObject:
execute sp_dba_getobj TRADECache Tbl Used# LastUsed CachedMb SizeMb Pct ------------------ ----- ----- ------------ -------- ------ --- default data cache TRADE 9 111215 15:21 439 5145 8
Lors de l’exécution de la requête, on va observer le volume total en cache augmenter régulièrement jusqu’à la taille maximum de la table (ou du pool du cache).
Analyse du contexte
On sait désormais ce qui ne va pas : un Table scan sur un objet absent
partiellement du cache, la durée d’exécution est ainsi dépendante de la
performance des disques. Sachant que la dégradation est subite et très
importante, il faut déterminer des facteurs changeants d’un plan d’exécution
La procédure
sp_help indique la date de création de la procédure
execute sp_help sp_testName Owner Object_type Create_date ------- ----- ---------------- ------------------- sp_test dbo stored procedure Apr 6 2008 10:51AM Parameter_name Type Length Prec Scale Param_order Mode -------------- -------- ------ ---- ----- ----------- ---- @process_date datetime 8 NULL NULL 1 in
Il est également intéressant de connaître la date de compilation de la procédure. Autrement dit : de quand date le plan ?
La table MDA monCachedProcedures donne cette information :
select o.name, o.crdate, cp.CompileDate from sysobjects o left join master.dbo.monCachedProcedures cp on cp.ObjectID=id and cp.DBID=db_id() where name in ( 'sp_test' ) and type='P'name crdate CompileDate ------------------------------ ------------------- ------------------- sp_test Apr 6 2008 10:51AM Dec 6 2011 5:13PM
La procédure est ancienne, pas de changement de code donc, mais la compilation est récente.
Taille des objets
execute sp_spaceused TRADE goname rowtotal reserved data index_size unused ----- -------- ---------- ---------- ---------- -------- TRADE 10533153 6090182 KB 5268914 KB 815654 KB 5614 KB
sp_spaceused retourne le nombre de lignes d’une table - basé sur les
statistiques - ainsi que la taille de l’objet et ses indexes.
Reserved = data + index_size + unusedASE propose en complément des fonctions utiles qui permettent d’obtenir ces
valeurs : data_pages, reserved_pages, used_pages et row_count.
select name, 'rowtotal' = row_count(db_id(),id) , 'Kb reserved' = reserved_pages(db_id(),id) * (@@maxpagesize/1024), 'Kb used' = used_pages(db_id(),id) * (@@maxpagesize/1024), 'Kb used_data' = data_pages(db_id(),id) * (@@maxpagesize/1024) from sysobjects where type='U' and name in ( 'TRADE', 'tmp_filtre')name rowtotal Kb reserved Kb used Kb used_data ------------------ ------------ ----------- ----------- ------------ tmp_filtre 748 64 32 28 TRADE 10533153 6090182 6084836 6084568
TRADE est une table de 6 Go pour 10 millions de lignes.
Description des indexes
execute sp_helpindex TRADEindex_name index_keys index_description ... --------------------- ------------------------------------------ ----------------- ... IDX_TRADE_PTF_INST_DT TRADING_DATE, PORTFOLIO_ID, INSTRUMENT_ID nonclustered ... IDX_TRADE_SETTLE_DT PORTFOLIO_ID, SETTLEMENT_DATE nonclustered ... TRADE_idx1 TRANS_ID nonclustered ... TRADE_idx2 RKS_TRANS_ID nonclustered ... IDX_TRADE_TX_TYP_ID TRANSACTION_TYPE_ID nonclustered ... IDX_TRADE_CRE_DT CREATED_ON nonclustered ... IDX_TRADE_MOD_DT UPDATED_ON nonclustered ... TRADE_ID_idx ID nonclustered ...
les procédure d’Ed Barlow sp__helpindex ou sp__revindex donnent des
résultats équivalents.
Les commandes DDL des indexes sont également disponibles par l’intermédiaire
du binaire ddlgen ($SYBASE/$SYBASE_ASE/bin/ddlgen).
ddlgen -SIDB_P1_ASE -Usa -P*** -TI -Ninvestment.dbo.TRADE.%-----------------------------------------------------------------------------
-- DDL for Index 'TRADE_idx1'
-----------------------------------------------------------------------------
print 'CREATING Index - "TRADE_idx1" >>>>>'
go
use investment
go
IF EXISTS (SELECT 1 FROM sysindexes i, sysobjects o, sysusers u WHERE o.id = i.id
AND o.uid = u.uid AND i.name = 'TRADE_idx1' AND u.name = 'dbo')
BEGIN
setuser 'dbo'
drop index TRADE.TRADE_idx1
END
go
IF (@@error != 0)
BEGIN
PRINT "Error CREATING Index 'TRADE_idx1'"
SELECT syb_quit()
END
go
create nonclustered index TRADE_idx1
on investment.dbo.TRADE(TRANS_ID)
go
...La procédure sp_spaceused vue précédemment permet également de connaître la
taille de chaque index d’une table
execute sp_spaceused TRADE,1index_name size reserved unused --------------------- --------- --------- -------- IDX_TRADE_PTF_INST_DT 161620 KB 162124 KB 504 KB IDX_TRADE_SETTLE_DT 85548 KB 86198 KB 650 KB TRADE_idx1 147108 KB 147648 KB 540 KB TRADE_idx2 77970 KB 78678 KB 708 KB IDX_TRADE_TX_TYP_ID 69352 KB 69940 KB 588 KB IDX_TRADE_CRE_DT 64242 KB 64282 KB 40 KB IDX_TRADE_MOD_DT 72158 KB 73466 KB 1308 KB TRADE_ID_idx 137656 KB 137752 KB 96 KB (1 row affected) name rowtotal reserved data index_size unused ----- -------- ---------- ---------- ---------- ------- TRADE 10533153 6090182 KB 5268914 KB 815654 KB 5614 KB
Tout comme la table, il est possible de mesurer la présence des indexes en
cache, toujours en interrogeant monCachedObjects
select 'Cache' = c.CacheName, 'Tbl' = o.name, 'Idx' = c.ObjectName , 'CachedMb' = c.CachedKB / 1024 , 'SizeMb' = c.TotalSizeKB / 1024 , 'Pct' = 100 * c.CachedKB / c.TotalSizeKB from sysobjects o join master.dbo.monCachedObject c on c.ObjectID=id and c.DBID=db_id() where o.name in ( 'TRADE', 'tmp_filtre' ) and o.type='U' order by ObjectName, IndexID goCache Tbl Idx CachedMb SizeMb Pct ------------------- ------------- ----------------------- -------- ----------- ----------- default data cache TRADE IDX_TRADE_CRE_DT 0 62 0 default data cache TRADE IDX_TRADE_MOD_DT 4 69 6 default data cache TRADE IDX_TRADE_PTF_INST_DT 117 155 75 default data cache TRADE IDX_TRADE_SETTLE_DT 18 81 22 default data cache TRADE IDX_TRADE_TX_TYP_ID 1 67 2 default data cache TRADE TRADE 439 5145 8 default data cache TRADE TRADE_ID_idx 1 133 1 default data cache TRADE TRADE_idx1 0 142 0 default data cache TRADE TRADE_idx2 2 75 3 default data cache tmp_filtre pk 0 0 7 default data cache tmp_filtre tmp_filtre 0 0 100
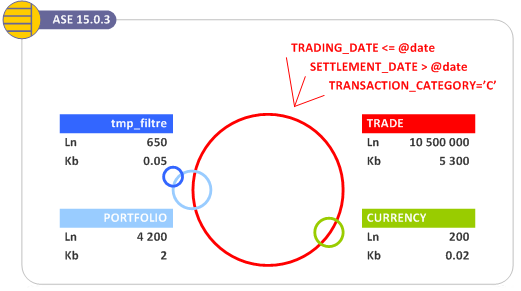
Notons que pour notre exemple, 3 filtres sont appliqués :
TRANSACTION_CATEGORY, TRADING_DATE et SETTLEMENT_DATE.
TRADING_DATEest en première position de l’index compositeIDX_TRADE_PTF_INST_DTSETTLEMENT_DATEest en deuxième position de l’index compositeIDX_TRADE_SETTLE_DTTRANSACTION_CATEGORYne fait partie d’aucun index.
Fragmentation de la table
La fragmentation mesure la *compacité* d’une table. Autrement dit, si toutes les pages d’une table sont contigües, l’effort pour les lire sur disque sera moins important que si elles sont dispersées.
De par sa nature (moteur OLTP) et sa méthode d’allocation des pages (par extent, soit 8 pages contigües), il est rare d’observer une fragmentation significative sur ASE.
Celle-ci peut néanmoins survenir parfois en fonction du type d’activité réalisée sur la table mais surtout du type de verrouillage de la table.
En effet, la gestion particulière des tables de type DOL (Data Only Locking)
peut provoquer des phénomènes de redirection ("forward") - données stockées
dans une autre page que celle prévue - ou un nombre important de lignes
"deleted", marquées comme tel pour accélérer la suppression mais physiquement
toujours présentes.
Toutes ces informations sont disponibles à travers la table système
systabstats et deux fonctions :
lockschemepour obtenir le mode de verrouillage.derived_statpour obtenir les ratios de fragmentation.
select 'Table' = o.name, 'Lock' = lockscheme(o.id), 'Rows' = rowcnt, 'RowsFwd' = forwrowcnt, 'RowsDel' = delrowcnt, 'Pgs' = pagecnt, 'PgsEmpty' = emptypgcnt, 'PgsUnused' = unusedpgcnt, 'ScanLIO' = dpagecrcnt, 'dpcr' = convert(smallint,100*derived_stat(a.id,a.indid,'dpcr')), 'drcr' = convert(smallint,100*derived_stat(a.id,a.indid,'drcr')), 'lgio' = convert(smallint,100*derived_stat(a.id,a.indid,'lgio')), 'sput' = convert(smallint,100*derived_stat(a.id,a.indid,'sput')), 'moddate' = convert(varchar(8),statmoddate,112) from sysobjects o join systabstats a on a.id=o.id and a.indid in ( 0,1 ) where o.name in ( 'TRADE', 'tmp_filtre' ) and o.type='U' order by 1Table Lock Rows RowFwd RowsDel Pgs PgsEmpty PgsUnused ScanLIO dpcr drcr lgio sput moddate ---------- -------- -------- ------ ------- ------- -------- --------- ------- ---- ---- ---- ---- -------- TRADE datarows 10533153 6 1105 2634457 0 484 330633 99 100 99 65 20111209 tmp_filtre allpages 748 0 0 13 0 2 2 100 100 100 17 20111206
La colonne ScanLIO (systabstats.dpagecrcnt) est intéressante, elle retourne
le nombre d’Extent I/O nécessaire pour réaliser un table scan et représente
donc l’effort système pour le réaliser. Cette valeur doit être très proche de
pages/8, un extent contenant toujours 8 pages.
On trouve également dans cette table le nombre de lignes 'forward' (RowFwd)
et 'delete' (RowDel) pour les tables DOL uniquement.
Les 4 colonnes obtenues via la fonction derived_stat signifient :
| Colonne | Nature | Description | |
|---|---|---|---|
dpcr |
Data Page Cluster Ratio |
Taux (100% = parfait) | Mesure l’ordre d’un index cluster. Pertinent donc uniquement pour des tables DOL possédant un index cluster, éventuellement des tables heap. Pour les tables APL, il ne peut pas y avoir de perte d’ordre. |
sput |
SPace UTilisation |
Taux (100% = parfait) | Taux d’utilisation de l’espace alloué, autrement dit, taux qui indique si de l’espace est perdu ou non. |
drcr |
Data Row Cluster Ratio |
Taux (100% = parfait) | Pertinent pour les indexes. |
lgio |
LarGe IO efficiency |
Taux (100% = parfait) | Taux de fragmentation impactant un table scan complet (full). |
La procédure SQLPAC sp_dba_statsdetail permet de collecter ces informations
execute sp_dba_statsdetail TRADE,1name Lck pages pgempty pgunused dpcr drcr lgio sput rowcnt rowfwd rowdel rowsize dpagecrcnt moddate ----- --- ------- ------- -------- ---- ---- ---- ---- -------- ------ ------ ------- ---------- -------- TRADE ROW 2634457 0 484 99 100 99 65 10533153 6 1105 329 330633 20111215
Sélectivité (optdiag)
Allons plus loin dans l’étude du plan avec l’analyse de la sélectivité de la table.
Sur la plus grosse table - TRADE - trois critères sont appliqués. La
sélectivité de la colonne par rapport aux valeurs des paramètres fournis est
importante. Ces paramètres couvrant 1% ou 90% des données, l’optimiseur
statistique va choisir d’utiliser tel ou tel index ou encore un balayage de
table .
Les statistiques des colonnes sont stockées dans la table sysstatistics,
dans des structures au format varbinary pas directement exploitables en ligne.
Ces données sont néanmoins traduites et accessibles avec l’utilitaire
$SYBASE/$SYBASE_ASE/bin/optdiag.
optdiag statistics investment.dbo.TRADE -Usa -P***La première partie concerne les statistiques relatives à la table. Une
partie d’entre elles sont les mêmes que celles obtenues grace à la fonction
derived_stat ou l’interrogation de systabstats.
OptDiag/15.0.3/EBF 16558 ESD#1/P/Solaris AMD64/OS 5.10/ase1503/2680/64-bit/OPT/Thu Mar 5 00:51:19 2009
Adaptive Server Enterprise/15.0.3/EBF 17690 ESD#1.1 RELSE/P/Solaris AMD64/OS 5.10/ase1503/2681/64-bit/FBO/Thu Aug 20 15:37:40 2009
Server name: "IDB_P1_ASE"
Specified database: "investment"
Specified table owner: "dbo"
Specified table: "TRADE"
Specified column: not specified
Table owner: "dbo"
Table name: "TRADE"
Statistics for table: "TRADE"
Data page count: 2634457
Empty data page count: 0
Data row count: 10533153.0000000000000000
Forwarded row count: 6.0000000000000000
Deleted row count: 1105.0000000000000000
Data page CR count: 330633.0000000000000000
OAM + allocation page count: 26569
First extent data pages: 0
Data row size: 329.0845115417956777
Parallel join degree: 0.0000000000000000
Unused page count: 484
OAM page count: 106
Derived statistics:
Data page cluster ratio: 0.9994247662841897
Space utilization: 0.6572198132906848
Large I/O efficiency: 0.9959895127616625Ensuite se succèdent toutes les statististiques relatives aux indexes, comme
par exemple les indexes IDX_TRADE_PTF_INST_DT et IDX_TRADE_SETTLE_DT qui nous
concernent ici :
Statistics for index: "IDX_TRADE_PTF_INST_DT" (nonclustered)
Index column list: "TRADING_DATE", "PORTFOLIO_ID", "INSTRUMENT_ID"
Leaf count: 79800
Empty leaf page count: 0
Data page CR count: 8948030.0000000000000000
Index page CR count: 10636.0000000000000000
Data row CR count: 9424139.0000000000000000
First extent leaf pages: 0
Leaf row size: 14.1463236126922300
Index height: 3
Derived statistics:
Data page cluster ratio: 0.0523494001868314
Index page cluster ratio: 0.9905334765485141
Data row cluster ratio: 0.1404045879943312
Space utilization: 0.9326850530421958
Large I/O efficiency: 0.9378525761564495ou
Statistics for index: "IDX_TRADE_SETTLE_DT" (nonclustered)
Index column list: "PORTFOLIO_ID", "SETTLEMENT_DATE"
Leaf count: 41954
Empty leaf page count: 0
Data page CR count: 8004090.0000000000000000
Index page CR count: 6393.0000000000000000
Data row CR count: 8807770.0000000000000000
First extent leaf pages: 0
Leaf row size: 7.6359075008214541
Index height: 3
Derived statistics:
Data page cluster ratio: 0.0947907657319493
Index page cluster ratio: 0.9687270151733908
Data row cluster ratio: 0.2184388017170416
Space utilization: 0.9575944149286382
Large I/O efficiency: 0.8204045144708908Enfin, le détail de la sélectivité de toutes les colonnes contenues dans un index est délivré, colonne par colonne.
Statistics for column: "TRADING_DATE"
Last update of column statistics: Dec 15 2011 12:33:30:183PM
Range cell density: 0.0003852781308391
Total density: 0.0004001307997297
Range selectivity: default used (0.33)
In between selectivity: default used (0.25)
Unique range values: 0.0002270042632487
Unique total values: 0.0002355712603062
Average column width: default used (8.00)
Histogram for column: "TRADING_DATE"
Column datatype: datetime
Requested step count: 1000
Actual step count: 1000
Sampling Percent: 0
Out of range Histogram Adjustment is DEFAULT.
Step Weight Value
1 0.00000000 <= "Feb 5 1933 11:59:59:996PM"
2 0.00101138 <= "Jan 4 2001 12:00:00:000AM"
3 0.00115141 <= "Jan 15 2001 12:00:00:000AM"
4 0.00110119 <= "Jan 23 2001 12:00:00:000AM"
5 0.00100540 <= "Jan 31 2001 12:00:00:000AM"
6 0.00105609 <= "Feb 9 2001 12:00:00:000AM"
7 0.00100749 <= "Feb 20 2001 12:00:00:000AM"
8 0.00100445 <= "Mar 1 2001 12:00:00:000AM"
9 0.00108429 <= "Mar 9 2001 12:00:00:000AM"
10 0.00110451 <= "Mar 21 2001 12:00:00:000AM"
...
990 0.00105856 <= "Nov 14 2011 12:00:00:000AM"
991 0.00116499 <= "Nov 17 2011 12:00:00:000AM"
992 0.00111249 <= "Nov 22 2011 12:00:00:000AM"
993 0.00110565 <= "Nov 25 2011 12:00:00:000AM"
994 0.00044716 <= "Nov 28 2011 12:00:00:000AM"
995 0.00000000 < "Nov 29 2011 12:00:00:000AM"
996 0.00040710 = "Nov 29 2011 12:00:00:000AM"
997 0.00148237 <= "Dec 2 2011 12:00:00:000AM"
998 0.00130521 <= "Dec 7 2011 12:00:00:000AM"
999 0.00122594 <= "Dec 12 2011 12:00:00:000AM"
1000 0.00067767 <= "Apr 16 2040 12:00:00:000AM"ou
Statistics for column: "SETTLEMENT_DATE"
Derived statistics from local partitions.
Last update of column statistics: Dec 15 2011 12:35:23:166PM
Range cell density: 0.0003885648681529
Total density: 0.0004030695332760
Range selectivity: default used (0.33)
In between selectivity: default used (0.25)
Unique range values: 0.0002346499375388
Unique total values: 0.0002434867299732
Average column width: 8.0000000000000000
Histogram for column: "SETTLEMENT_DATE"
Column datatype: datetime
Requested step count: 1000
Actual step count: 1000
Sampling Percent: 0
Out of range Histogram Adjustment is ON.
Step Weight Value
1 0.00000000 <= "Feb 5 1933 11:59:59:996PM"
2 0.00101973 <= "Jan 8 2001 12:00:00:000AM"
3 0.00106958 <= "Jan 17 2001 12:00:00:000AM"
4 0.00103682 <= "Jan 25 2001 12:00:00:000AM"
5 0.00111230 <= "Feb 2 2001 12:00:00:000AM"
6 0.00105695 <= "Feb 13 2001 12:00:00:000AM"
7 0.00100226 <= "Feb 22 2001 12:00:00:000AM"
8 0.00112360 <= "Mar 6 2001 12:00:00:000AM"
9 0.00108467 <= "Mar 14 2001 12:00:00:000AM"
10 0.00107897 <= "Mar 27 2001 12:00:00:000AM"
...
990 0.00109796 <= "Nov 15 2011 12:00:00:000AM"
991 0.00105562 <= "Nov 18 2011 12:00:00:000AM"
992 0.00116613 <= "Nov 23 2011 12:00:00:000AM"
993 0.00107508 <= "Nov 28 2011 12:00:00:000AM"
994 0.00084932 <= "Nov 30 2011 12:00:00:000AM"
995 0.00000000 < "Dec 1 2011 12:00:00:000AM"
996 0.00060390 = "Dec 1 2011 12:00:00:000AM"
997 0.00135373 <= "Dec 6 2011 12:00:00:000AM"
998 0.00123249 <= "Dec 9 2011 12:00:00:000AM"
999 0.00124350 <= "Dec 14 2011 12:00:00:000AM"
1000 0.00081865 <= "May 19 8200 12:00:00:000AM"optdiag retourne également la sélectivité des combinaisons d’indexes
multi-colonnes (ou composites).
La sélectivité des deux colonnes TRADING_DATE et SETTLEMENT_DATE est
intéressante. Les valeurs de la colonne SETTLEMENT_DATE comprises entre le 9 et
le 14 décembre 2011 représentent 0,12% des lignes (0.00124350*100) de même que
pour les valeurs de la colonne TRADING_DATE entre le 7 et le 12 décembre
2011.
Les valeurs sont très proches toutefois la requête utilise ces valeurs comme
bornes. Aussi, si la valeur de date est très basse - proche de 2001 - l’index
sur SETTLEMENT_DATE est plus pertinent. Si au contraire, elle est proche de
2011, alors l’index sur TRADING_DATE est plus efficace. Si elle est située à mi
chemin, vers 2005, le table scan sera sans doute plus pertinent.
C’est à ce type de choix qu’est dévolu l’optimiseur statistique.
Ce comportement est confirmé en forçant la recompilation de la procédure lors de son exécution :
set showplan on execute sp_test '20010101' with recompile... | | | | | FROM TABLE | | | | | TRADE | | | | | t | | | | | Index : IDX_TRADE_PTF_INST_DT | | | | | Forward Scan. | | | | | Positioning by key. | | | | | Keys are: | | | | | TRADING_DATE ASC | | | | | PORTFOLIO_ID ASC ...
execute sp_test '20050101' with recompile| | | | | |SCAN Operator (VA = 0) | | | | | | FROM TABLE | | | | | | TRADE | | | | | | t | | | | | | Table Scan.
execute sp_test '20110101' with recompile| | | | |SCAN Operator (VA = 2) | | | | | FROM TABLE | | | | | TRADE | | | | | t | | | | | Index : IDX_TRADE_SETTLE_DT | | | | | Forward Scan. | | | | | Positioning by key. | | | | | Keys are: | | | | | PORTFOLIO_ID ASC | | | | | SETTLEMENT_DATE ASC
Pertinence des statistiques
On l’a aperçu avec la commande optdiag, deux types de statistiques sont
maintenues pour une table :
- la structure : nombre de lignes, pages, extents. Ces informations sont maintenues en temps réel par le système.
- le contenu : les histogrammes, leur bornes, leur densité : ces informations sont maintenues par les commandes
UPDATE [ table|index|all ] STATISTICS.
La pertinence de ces deux informations est primordiale. optdiag donne les dates de mise à jour de ces informations, il existe néanmoins un moyen de
mesurer le degré de changement d’une table, partition ou une colonne,
La fonction DATACHANGE retourne le degré de changement (%)
d’une table depuis la dernière commande UPDATE STATS
IDB_P1_ASE.investment> select datachange('TRADE',null,null);0.076557
Ici, moins de 1% de changement depuis le dernier lancement de la commande
UPDATE STATISTICS: les statistiques sont à jour.
Coûts du plan d’exécution
Voici présentées plusieurs méthodes pour estimer le coût du plan.
La logique Sybase ASE est dite 'cost based optimiser', cela signifie que
l’accès aux données est déterminé en fonction de la sélectivité des colonnes,
de la taille des objets, des modèles de jointures possibles mais aussi de
l’effort nécessaire à la collecte d’informations. L’effort est mesuré en termes
de consommation cpu, de lecture de données déjà en mémoire (lectures logiques)
et de lectures nécessaires sur disque (lectures physiques).
Chacune de ces opérations a une importance pondérée, permettant de déterminer un 'coût', le moins élevé est jugé le meilleur. c’est l’étape de compilation.
Voici une illustration simplifiée des choix d’indexes possibles que l’optimiseur a à prendre en charge
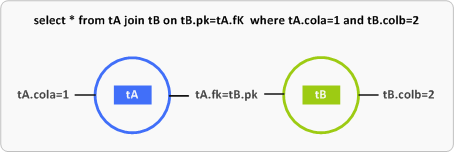
- L’optimiseur choisit de lire la table
tAa partir d’un index portant sur la colonne *cola* et adressetBpar l’index *pk*. - Au contraire, la lecture commence par la table
tBà partir d’un index portant sur la colonne *colb* ettAest adressée par l’index portant surfk. - On multiplie ces deux possibilités en incluant des balayages de tables (
table scan) sur l’une, l’autre ou les deux tables. - On multiplie ces choix par des méthodes de jointures : jointures par boucles imbriquées (Nested Loop), jointures par fusion (
merge), jointures par hâchage (hash).
C’est donc le rôle dévolu à l’optimiseur statistique. Pour cette raison, bon nombre des commandes évoquées ci-dessous vont fournir un résultat verbeux; le système nous permet de *voir* chacune des combinaisons testées, son coût et dès lors, son élimination ou son choix.
set showplan on
Méthode historique, elle retourne le même résultat que celui obtenu via
sp_showplan sur un processus en cours d’exécution :
set showplan on go execute sp_test '20111213' goQUERY PLAN FOR STATEMENT 1 (at line 1). STEP 1 The type of query is EXECUTE. Parse and Compile Time 0. Adaptive Server cpu time: 0 ms. QUERY PLAN FOR STATEMENT 1 (at line 0). STEP 1 The type of query is DECLARE. QUERY PLAN FOR STATEMENT 2 (at line 5). STEP 1 The type of query is CREATE TABLE. STEP 2 The type of query is INSERT. 5 operator(s) under root |ROOT:EMIT Operator (VA = 5) | | |INSERT Operator (VA = 4) | | The update mode is direct. | | | | |HASH VECTOR AGGREGATE Operator (VA = 3) | | | GROUP BY | | | Evaluate Grouped SUM OR AVERAGE AGGREGATE. | | | Using Worktable1 for internal storage. | | | Key Count: 1 | | | | | | |NESTED LOOP JOIN Operator (VA = 2) (Join Type: Inner Join) | | | | | | | | |SCAN Operator (VA = 0) | | | | | FROM TABLE | | | | | tmp_filtre | | | | | f | | | | | Using Clustered Index. | | | | | Index : pk | | | | | Forward Scan. | | | | | Positioning by key. | | | | | Keys are: | | | | | PORTFOLIO_ID ASC | | | | | Using I/O Size 16 Kbytes for data pages. | | | | | With LRU Buffer Replacement Strategy for data pages. | | | | | | | | |SCAN Operator (VA = 1) | | | | | FROM TABLE | | | | | TRADE | | | | | t | | | | | Index : IDX_TRADE_SETTLE_DT | | | | | Forward Scan. | | | | | Positioning by key. | | | | | Keys are: | | | | | PORTFOLIO_ID ASC | | | | | SETTLEMENT_DATE ASC | | | | | Using I/O Size 2 Kbytes for index leaf pages. | | | | | With LRU Buffer Replacement Strategy for index leaf pages. | | | | | Using I/O Size 2 Kbytes for data pages. | | | | | With LRU Buffer Replacement Strategy for data pages. | | | | TO TABLE | | #tmp | | Using I/O Size 16 Kbytes for data pages.
set statistics io, time on
Plus précises, et surtout plus utiles dans le cadre d’une optimisation, des statistiques sont fournies récapitulant le coût CPU et I/O d’un traitement.
set statistics io, time on go execute sp_test '20111213' goParse and Compile Time 0. Adaptive Server cpu time: 0 ms. Parse and Compile Time 0. Adaptive Server cpu time: 0 ms. Table: #tmp scan count 1, logical reads: (regular=330 apf=0 total=330), physical reads: (regular=0 apf=0 total=0), apf IOs used=0 Table: Worktable1 scan count 1, logical reads: (regular=5 apf=0 total=5), physical reads: (regular=0 apf=0 total=0), apf IOs us ed=0 Table: tmp_filtre (f) scan count 1, logical reads: (regular=14 apf=0 total=14), physical reads: (regular=0 apf=0 total=0), apf IOs used=0 Table: TRADE (t) scan count 729, logical reads: (regular=11748 apf=0 total=11748), physical reads: (regular=0 apf=0 total=0), apf IOs used=0 Total writes for this command: 0 Execution Time 0. Adaptive Server cpu time: 0 ms. Adaptive Server elapsed time: 16 ms.
Les options peuvent être définies individuellement (set statistics io
on/off, set statistics time on/off).
La procédure dure 16 millisecondes, dont la principale charge est la lecture
de la table TRADE (t). Le nombre de scan ainsi que le nombre de lectures
logiques indiquent la nature de la lecture de cette table.
La table TRADE est accedée 729 fois, pour un total de 11748 I/Os, on peut
donc deviner sans connaître le plan que la table est lue en mode 'Nested Loop'.
Notons qu’il n’y a aucune lecture physique, toutes les données souhaitées
sont en cache. Il n’y a pas non plus d'apf (asynchronous prefetch). Cette
méthode de lecture rapide - large I/Os - est utilisée dans le cadre d’un
balayage de table (table scan).
Notons enfin que les I/Os de la table temporaire #tmp sont marqués en
"logical reads" alors qu’il s’agit d’écritures. Étrangeté.
La durée d’exécution est utile mais pas forcément primordiale dans le cadre d’une étude de performance. Elle dépend de la charge de la machine et de sa puissance. Le nombre d’I/Os lui est constant et fournit donc une mesure de référence bien plus fiable, sachant que moins il y a d’I/Os, plus rapide est la requête.
set statistics plancost et le traceflag 9529
Les options set showplan et set statistics io,time
peuvent être combinées. set plancost délivre un résultat
équivalent agrémenté de deux informations très utiles :
- une représentation *graphique* du plan
- l’affichage des différences entre les coûts estimés et les coûts réels.
set statistics plancost on go execute sp_test '20111213' go==================== Lava Operator Tree ==================== Emit (VA = 6) r:316 er:3200 cpu: 100 / Insert #tmp (VA = 5) r:316 er:3200 l:329 el:9 p:0 ep:9 / GroupSorted Grouping (VA = 4) r:316 er:3200 / NestLoopJoin Inner Join (VA = 3) r:3992 er:3200 / \ Sort IndexScan (VA = 1) IDX_TRADE_SETTLE (t) r:729 er:728 (VA = 2) l:6 el:6 r:3992 er:3200 p:0 ep:0 l:48303 el:0 cpu: 0 bufct: 24 p:0 ep:0 / IndexScan pk (f) (VA = 0) r:729 er:728 l:14 el:0 p:0 ep:0 ============================================================
Les codes de lecture sont:
- r = rows : nombre de lignes
- l = lio : I/Os logiques
- p = pio : I/Os physiques
- cpu = cpu : nombre de cycles
- prefixe e : estimate
Le 'coût' d’une requête est évalué à partir des estimations cpu, pio et lio selon une formule équivalente à celle-ci :
Les pondérations peuvent varier en fonction de la version et/ou du type d’optimisation choisi, mais les proportions générales restent les mêmes.
Les différences entre l’estimation et la réalisation sont *anormales* au sens ou celà signifie que l’optimiseur n’a pas une vision correcte des données qu’il manipule. Attention : cela ne signifie pas que le plan choisi n’est pas optimal.
Ainsi on observe que pour la table TRADE - alias (t) - les données sont
accédées par l’index IDX_TRADE_SETTLE pour un nombre de lignes de 4053 alors
que 1144 lignes étaient estimées.
Petit test : on a vu plus haut avec optdiag que l’histogramme représentant
la colonne TRADING_DATE contenait 1000 entrées avec une période d’une semaine
environ par plage. Observons la différence de comportement avec un histogramme
plus détaillé sur 2000 entrées :
update index statistics TRADE using 2000 values go set statistics plancost on go... / \ IndexScan IndexScan pk (f) IDX_TRADE_SETTLE (t) (VA = 0) (VA = 1) r:729 er:731 r:4053 er:3204 l:14 el:0 l:11748 el:0 p:0 ep:0 p:0 ep:0
L’estimation des lignes est désormais bien plus proche de la réalité sans toutefois changer le plan d’exécution.
Une autre manière de voir le même contenu, sans la mise en forme
hiérarchique, est accessible via le traceflag 9529
dbcc traceon(3604,9529) go execute sp_test '20111213' go... Execution Contest statistics: Buffer Ct: 24, HWM Buffer Ct: 24 Statement No: 2 ====================== Lava Operator Tree ==================== |Emit (VA = 6, LSTATE_CLOSED) | Rows: act:316 est:3200 | cpu: 100 | | |Insert (VA = 5, LSTATE_CLOSED) | |#tmp | | Rows: act:316 est:3200 | | Lios: act:329 est:9 | | Pios: act:0 est:9 | | | | |GroupSorted (VA = 4, LSTATE_CLOSED) | | |Grouping | | | Rows: act:316 est:3200 | | | | | | |NestLoopJoin (VA = 3, LSTATE_CLOSED) | | | |Inner Join | | | | Rows: act:3992 est:3200 | | | | | | | | |Sort (VA = 1, LSTATE_CLOSED) | | | | | Rows: act:729 est:728 | | | | | Lios: act:6 est:6 | | | | | Pios: act:0 est:0 | | | | | cpu: 0 bufct: 24 | | | | | | | | | | |IndexScan (VA = 0, LSTATE_CLOSED) | | | | | |pk (f) | | | | | | Rows: act:729 est:728 | | | | | | Lios: act:14 est:0 | | | | | | Pios: act:3 est:0 | | | | | | | | |IndexScan (VA = 2, LSTATE_CLOSED) | | | | |IDX_TRADE_SETTLE (t) | | | | | Rows: act:3992 est:3200 | | | | | Lios: act:48303 est:0 | | | | | Pios: act:3023 est:0 ==============================================================
L’optimiseur et le coût des jointures
Les chapitres suivants sont présentés à titre informatif. Au quotidien, il est rare d’avoir à exploiter ces informations, les sorties sont souvent verbeuses et pas toujours aisées à manipuler. Sybase ASE délivre des informations très détaillées sur le processus de décision de ses plans d’exécution, informations qui permettent de mieux comprendre le fonctionnement du moteur.
set option show_search_engine
Cette option, introduite avec ASE 15, est l’équivalente de l’ancienne
instruction dbcc traceon(3604,310).
Elle montre le processus de décision de l’optimiseur statistique, en particulier les permutations de tables et les algorithmes utilisés amenant au choix des indexes.
dbcc traceon(3604)
go
set option show_search_engine on
go
execute sp_test '20111213' with recompile
goEn l’absence de l’option 'with recompile' le système va utiliser le plan
compilé en cache et la sortie ne montrera rien.
La première partie du résultat va décrire le contexte d’exécution de la requête et lister toutes les options prises en compte par l’optimiseur.
OptCriteria:
append_union_all alternative_greedy_search distinct_hashing
distinct_sorted distinct_sorting group_hashing
group_sorted hash_union_distinct index_union
merge_join merge_union_all merge_union_distinct
nary_nl_join nl_join order_sorting
parallel_query replicated_partition streaming_sort
store_index use_mixed_dt_sarg_under_specialor
Optimization Goal: allrows_mix
Optimization Learning mode disabled.
Optimization Timeout limit: 40%
Server Level Optimization Timeout has been set.
Optimization query tuning time limit enabled.
The compiler will use the current best plan when 40%(Optimization Timeout limit) of average execution time is exceeded.
Optimization query tuning mem limit enabled.
The compiler will use the current best plan when 10%(Max Resource Granularity) of procedure cache is exceeded.Ce qu’il faut retenir : de nombreuses combinaisons de jointures sont évaluées et un coût est attribué suivant la formule vue plus haut. La combinaison la plus efficace est retenue.
Dans l’exemple courant :
grep "Permutation Order" show_search_engine.txtPermutation Order: Gt3( CURRENCY c ) |X| Gt2( TRADE t ) |X| Gt5( tmp_filtre f ) |X| Gt4( PORTFOLIO p ) Permutation Order: Gt3( CURRENCY c ) |X| Gt2( TRADE t ) |X| Gt5( tmp_filtre f ) |X| Gt4( PORTFOLIO p ) Permutation Order: Gt3( CURRENCY c ) |X| Gt2( TRADE t ) |X| Gt4( PORTFOLIO p ) |X| Gt5( tmp_filtre f ) Permutation Order: Gt3( CURRENCY c ) |X| Gt5( tmp_filtre f ) |X| Gt4( PORTFOLIO p ) |X| Gt2( TRADE t ) Permutation Order: Gt2( TRADE t ) |X| Gt5( tmp_filtre f ) |X| Gt3( CURRENCY c ) |X| Gt4( PORTFOLIO p ) Permutation Order: Gt2( TRADE t ) |X| Gt5( tmp_filtre f ) |X| Gt4( PORTFOLIO p ) |X| Gt3( CURRENCY c ) Permutation Order: Gt2( TRADE t ) |X| Gt4( PORTFOLIO p ) |X| Gt3( CURRENCY c ) |X| Gt5( tmp_filtre f ) Permutation Order: Gt5( tmp_filtre f ) |X| Gt3( CURRENCY c ) |X| Gt4( PORTFOLIO p ) |X| Gt2( TRADE t ) Permutation Order: Gt5( tmp_filtre f ) |X| Gt2( TRADE t ) |X| Gt3( CURRENCY c ) |X| Gt4( PORTFOLIO p ) Permutation Order: Gt5( tmp_filtre f ) |X| Gt2( TRADE t ) |X| Gt4( PORTFOLIO p ) |X| Gt3( CURRENCY c ) Permutation Order: Gt5( tmp_filtre f ) |X| Gt4( PORTFOLIO p ) |X| Gt3( CURRENCY c ) |X| Gt2( TRADE t ) Permutation Order: Gt4( PORTFOLIO p ) |X| Gt2( TRADE t ) |X| Gt3( CURRENCY c ) |X| Gt5( tmp_filtre f ) Permutation Order: Gt4( PORTFOLIO p ) |X| Gt2( TRADE t ) |X| Gt5( tmp_filtre f ) |X| Gt3( CURRENCY c )
set option show_pio_costing
select ObjectName, IndexID, CachedKB, TotalSizeKB, CacheName from master..monCachedObject where ObjectID=1235587540;ObjectName IndexID CachedKB TotalSizeKB CacheName ------------------------------ ----------- ----------- ----------- ------------------------------ PORTFOLIO_11 10 8 34 default data cache PK_PORTFOLIO 2 58 58 default data cache PORTFOLIO_DALI_CODE 6 24 42 default data cache PORTFOLIO 0 1710 1710 default data cache
L’option show_pio_costing montre les évaluations successives
réalisées pour mesurer l’effort de lecture des informations sur disque.
La sortie est également complexe à analyser, néanmoins, les valeurs PIO
(I/Os physiques) et LIO (I/Os logiques) donnent quelques clés de lecture :
dbcc traceon(3604) go set option show_pio_costing on go execute sp_test '20111213' with recompile goSTART NEW COSTING ( PopIndScan IDX_TRADE_PTF_INST_DT TRADE t ) cost: [C=0 A=0 1] order: none part: Roundrobin :{} Degree(s):[1] START BUFFER CACHE COSTING ( BUF CACHE FOR INDEX SCAN - IDX_TRADE_PTF_INST_DT, CacheId=5, MassSize=16384, Fraction=1, MRU=0, WashSize=208896, PoolSize=3046400, CacheAvail=3046400, FrontierCt=1, 2K_PIO=80466.06, PageCR=0.9760019, MassSize=16384, Outer=1, InOrder=1.058422e+07, ScanPg=80463.06, LIO=80466.06, PIO=11747.91 ) END BUFFER CACHE COSTING START POP PIO COSTING ( BUF CACHE FOR INDEX SCAN - IDX_TRADE_PTF_INST_DT, CacheId=5, MassSize=16384, Fraction=1, MRU=0, WashSize=208896, PoolSize=3046400, CacheAvail=3046400, FrontierCt=1, 2K_PIO=80466.06,PageCR=0.9760019, MassSize=16384, Outer=1, InOrder=1.058422e+07, ScanPg=80463.06, LIO=80466.06, PIO=11747.91 ) (PIO FOR INDEX SCAN - IDX_TRADE_PTF_INST_DT, CacheId=5, MassSize=16384, Fraction=1, MRU=0, WashSize=208896, PoolSize=3046400, CacheAvail=3046400, FrontierCt=11747.91, 2K_PIO=80466.06, PageCR=0.9760019, MassSize=16384, Outer=1, InOrder=1.058422e+07, ScanPg=80463.06, LIO=80466.06, PIO=11747.91 ) END POP PIO COSTING START NEW COSTING ( PopRidJoin ( PopIndScan IDX_TRADE_PTF_INST_DT TRADE t ) ) cost: [C=0 A=0 1] order: none part: Roundrobin :{} Degree(s):[1] START BUFFER CACHE COSTING ( BUF CACHE FOR INDEX SCAN - IDX_TRADE_PTF_INST_DT, CacheId=5, MassSize=16384, Fraction=1, MRU=0, WashSize=208896, PoolSize=3046400, CacheAvail=3046400, FrontierCt=1, 2K_PIO=80466.06, PageCR=0.9760019, MassSize=16384, Outer=1, InOrder=1.058422e+07, ScanPg=80463.06, LIO=80466.06, PIO=11747.91 ) (BUF CACHE FOR RID SCAN - TRADE, CacheId=5, MassSize=16384, Fraction=1, MRU=1, WashSize=208896, PoolSize=3046400, CacheAvail=208896, FrontierCt=1, Outer=1, InOrder=1, ScanPg=8372716, LIO=0, PIO=7106872) END BUFFER CACHE COSTING START POP PIO COSTING (BUF CACHE FOR INDEX SCAN - IDX_TRADE_PTF_INST_DT, CacheId=5, MassSize=16384, Fraction=1, MRU=0, WashSize=208896, PoolSize=3046400, CacheAvail=3046400, FrontierCt=1, 2K_PIO=80466.06, PageCR=0.9760019, MassSize=16384, Outer=1, InOrder=1.058422e+07, ScanPg=80463.06, LIO=80466.06, PIO=11747.91) (PIO FOR INDEX SCAN - IDX_TRADE_PTF_INST_DT, CacheId=5, MassSize=16384, Fraction=0.05324375, MRU=0, WashSize=208896, PoolSize=3046400, CacheAvail=162201.8, FrontierCt=11747.91, 2K_PIO=80466.06, PageCR=0.9760019, MassSize=16384, Outer=1, InOrder=1.058422e+07, ScanPg=80463.06, LIO=80466.06, PIO=11747.91) (BUF CACHE FOR RID SCAN - TRADE, CacheId=5, MassSize=16384, Fraction=1, MRU=1, WashSize=208896, PoolSize=3046400, CacheAvail=208896, FrontierCt=1, Outer=1, InOrder=1, ScanPg=8372716, LIO=0, PIO=7106872) (PIO FOR RID SCAN - TRADE, CacheId=5, MassSize=16384, Fraction=0.9467562, MRU=1, WashSize=208896, PoolSize=3046400, CacheAvail=208896, FrontierCt=208896, Outer=1, InOrder=1.058422e+07, ScanPg=8372716, LIO=0, PIO=7106872) END POP PIO COSTING START NEW COSTING ...
set option show_lio_costing
La nouvelle option Sybase 15 set show_lio_costing correspond à
l’ancienne option dbcc traceon(302), sans doute la plus intéressante des
options dans le cadre d’un audit. Elle permet d’observer les éléments pris en
compte par l’optimiseur, en particulier la sélectivité des indexes et donc le
processus de décision guidant à leur usage.
dbcc traceon(3604) go set option show_lio_costing on go execute sp_test '20111213' with recompile go... Estimating selectivity for table 'TRADE' Table scan cost is 1.053315e+07 rows, 2634457 pages, The table (Datarows) has 1.053315e+07 rows, 2634457 pages, Data Page Cluster Ratio 0.9996182 TRADING_DATE <= Dec 13 2011 12:00:00:000AM Estimated selectivity for TRADING_DATE, selectivity = 0.9993974, SETTLEMENT_DATE > Dec 13 2011 12:00:00:000AM Estimated selectivity for SETTLEMENT_DATE, selectivity = 0.002837884, TRANSACTION_CATEGORY = 'C' Estimated selectivity for TRANSACTION_CATEGORY, selectivity = 0.1, Search argument selectivity is 0.0002836173. using table prefetch (size 16K I/O) Large IO selected: The number of leaf pages qualified is > MIN_PREFETCH pages in data cache 'default data cache' (cacheid 0) with MRU replacement MRU selected: More than 1/2 of the pool is swept out by the scan ...
Comme souvent avec les commandes set option ... la sortie est
verbeuse. On y trouve une estimation de la sélectivité des tables, des indexes,
pour chacune des combinaisons de jointures testées.
On observe ici bon nombre d’éléments très intéressants :
- Le filtre sur la colonne
TRADING_DATEn’est pas du tout discriminant.selectivity = 0.9993974signifie que 99,93% des données correspondent au filtreTRADING_DATE < '20111213'. - Au contraire, le filtre sur la colonne
SETTLEMENT_DATEest excellent.selectivity = 0.002837884, ce qui signifie que 0,28% des données correspondent au filtreSETTLEMENT_DATE > '20111213'. - La sélectivité du filtre sur la colonne
TRANSACTION_CATEGORYest estimée à 0.1. Il s’agit d’une valeur par défaut, un nombre *magique* utilisé lorsqu’une information n’est pas disponible. - L’information "
Largio IO selected: The number of leaf pages qualified is > MIN_PREFETCH pages" signifie que le nombre de pages à lire est suffisamment important (> MIN_PREFETCH) pour déclencher une méthode d’accès en mode Large I/O (par extent, soit par blocs de 8 pages). - Enfin, une information et une alerte : "
MRU selected: More than 1/2 of the pool is swept out by the scan". Cette alerte signifie que la gestion du cache sera réalisée en modeMRU(FIFO) : autrement dit, les données seront montées en cache, mais que le volume impliqué risque de vider le pool.
L’interêt de cette commande est de donner des clés pour comprendre pourquoi une option de plan d’exécution qui paraîtrait naturelle n’est pas prise en compte : bien souvent il s’agit de problèmes de typages invalides ou de statistiques obsolètes.
Conclusion
La procédure n’est pas nouvelle, les statistiques sont correctes, le système fonctionne convenablement et pourtant les performances sont dégradées.
La cause du problème est liée au cache de procédures : le meilleur plan d’exécution déterminé est sauvegardé dans la mémoire de l’instance et réutilisé lors de l’appel suivant de la procédure. Le système gagne ainsi un temps précieux; les performances générales du traitement sont améliorées et la consommation système abaissée, augmentant de fait une meilleure montée en charge du moteur.
Dans le cas présent l’instance a été redémarrée de manière exceptionnelle en
pleine journée, dans un contexte particulier de reprise d’historique. Lors du
premier lancement de la procédure, la date donnée en paramètre était extrêment
lointaine dans le passé, contrairement à l’habitude, provoquant alors un 'Table
Scan' normal dans ce cas. Ce plan a donc été sauvegardé et la nuit de batch
suivante a donc été pénalisée par le réutilisation de cette méthode d’accès
devenue inadaptée.
La solution à court terme a consister à lancer la commande
sp_recompile sur l’une des tables impliquées, commande qui
provoque le recalcul du plan avant batch. Dans un second temps, l’option
with recompile a été ajoutée dans la procédure. L’option
with recompile provoque la recompilation à chaque exécution de la
procédure.
execute sp_recompile TRADEEach stored procedure and trigger that uses table 'TRADE' will be recompiled the next time it is executed.
Annexe
Annexe 1 - la valeur unused dans sp_spaceused
Une valeur élevée dans la colonne unused retournée par la procédure
sp_spaceused est un indice - mais pas une preuve - de fragmentation. L’unité de
stockage d’une table est la page, et les pages sont allouées par *Extent*
(groupe de 8 pages). Un extent ne contient des informations que pour un seul
objet, aussi, il y a toujours *naturellement* de l’espace inutilisé (unused).
Illustration :
create table test ( a int ) go execute sp_spaceused test goname rowtotal reserved data index_size unused ---- -------- -------- ---- ---------- ------ test 0 16 KB 2 KB 0 KB 14 KB
La table est vide et pourtant occupe 16K (1 extent de 8 pages de 2K), dont 1
page de données OAM (Object Allocation Map) et 14K 'unused' (7 * 2K).